
Qu’est-ce que le DeepFake ?

Procédé de plus en plus présent à la télévision et sur les réseaux sociaux, le DeepFake est devenu un véritable phénomène. À la fois bluffant et effrayant, nous allons vous faire découvrir ce qu’est le DeepFake, son fonctionnement et son processus de création à travers un voyage au cœur de l’Intelligence Artificielle.
Le deepfake c’est quoi ?
Contraction de « Deep Learning » et « Vidéo Fake », il correspond simplement à une vidéo truquée réalisée à partir d’une technique d’Intelligence Artificielle. Historiquement, le trucage vidéo n’a pas de connotation négative. Il est en constante évolution, permettant à des industries telles que le cinéma d’améliorer considérablement leurs réalisations.
Ici, la technique employée ouvre la voie à une quantité infinie de possibilités, créant beaucoup de fantasmes mais aussi source de débat dans certains cas. Cet article, lui, ne portera pas sur les bienfaits ou les méfaits du DeepFake mais bien sur son fonctionnement à travers l’IA.
En DeepFake, nous pouvons dresser une typologie des fakes en les classant de la plus simple à la plus sophistiquée :
- Le Lip Sync
- Le Face Swap
- Le Face to Face
Le Lip Sync, comme son nom l’indique correspond à la synchronisation des lèvres. Vous prenez la vidéo d’une personne et vous écrivez son nouveau discours. Un imitateur lit le discours avec la voix de la personne choisie et l’algorithme se charge du reste, à savoir la modification des lèvres afin qu’elles correspondent au nouveau discours. Avec cette technique, le truquage de la parole n’est pas encore au point mais les évolutions promettent de grandes améliorations.
La troisième et dernière technique est celle du Face to Face, une combinaison des deux autres typologies présentées ci-dessus. L’objectif reste le même : faire prononcer à quelqu’un un discours qu’il n’a jamais fait.
Comment ça marche ?
Rentrons un peu plus dans la technique et découvrons ce qui se cache derrière ces rendus impressionnants, parfois plus vrais que nature.
Les réseaux de neurones
Le « Deep Learning » est un « réseau de neurones » nettement amélioré et beaucoup plus gros.
Ce sont des neurones artificiels, une copie informatique de neurones biologiques. Ils sont généralement organisés en trois couches comme nous pouvons le voir sur le schéma.
Chaque neurone est généralement interconnecté avec les neurones de la couche inférieure, illustrés ici par les traits. Une connexion est représentée par un « poids », calculé durant la phase d’apprentissage.
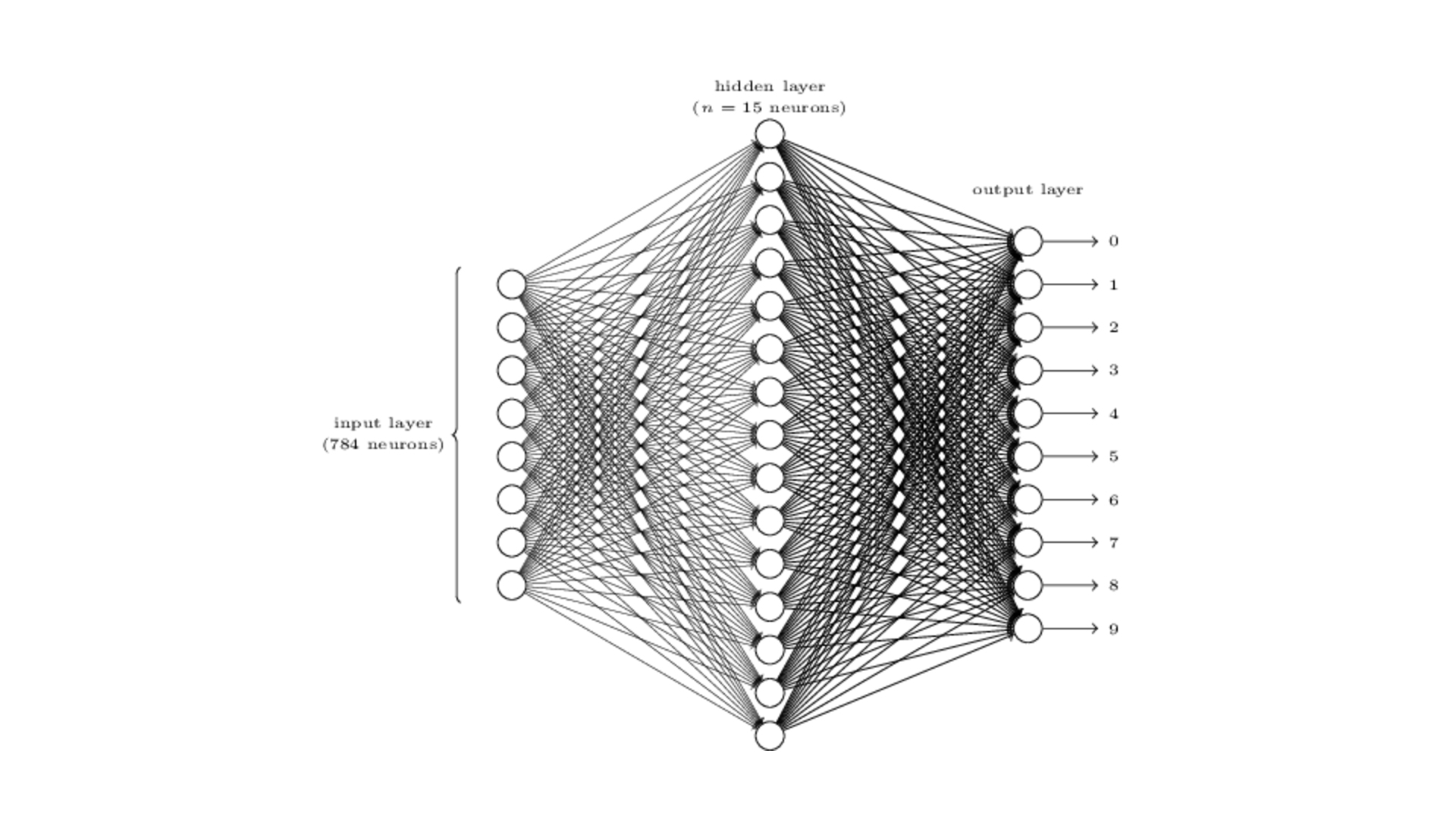
Le Deep Learning
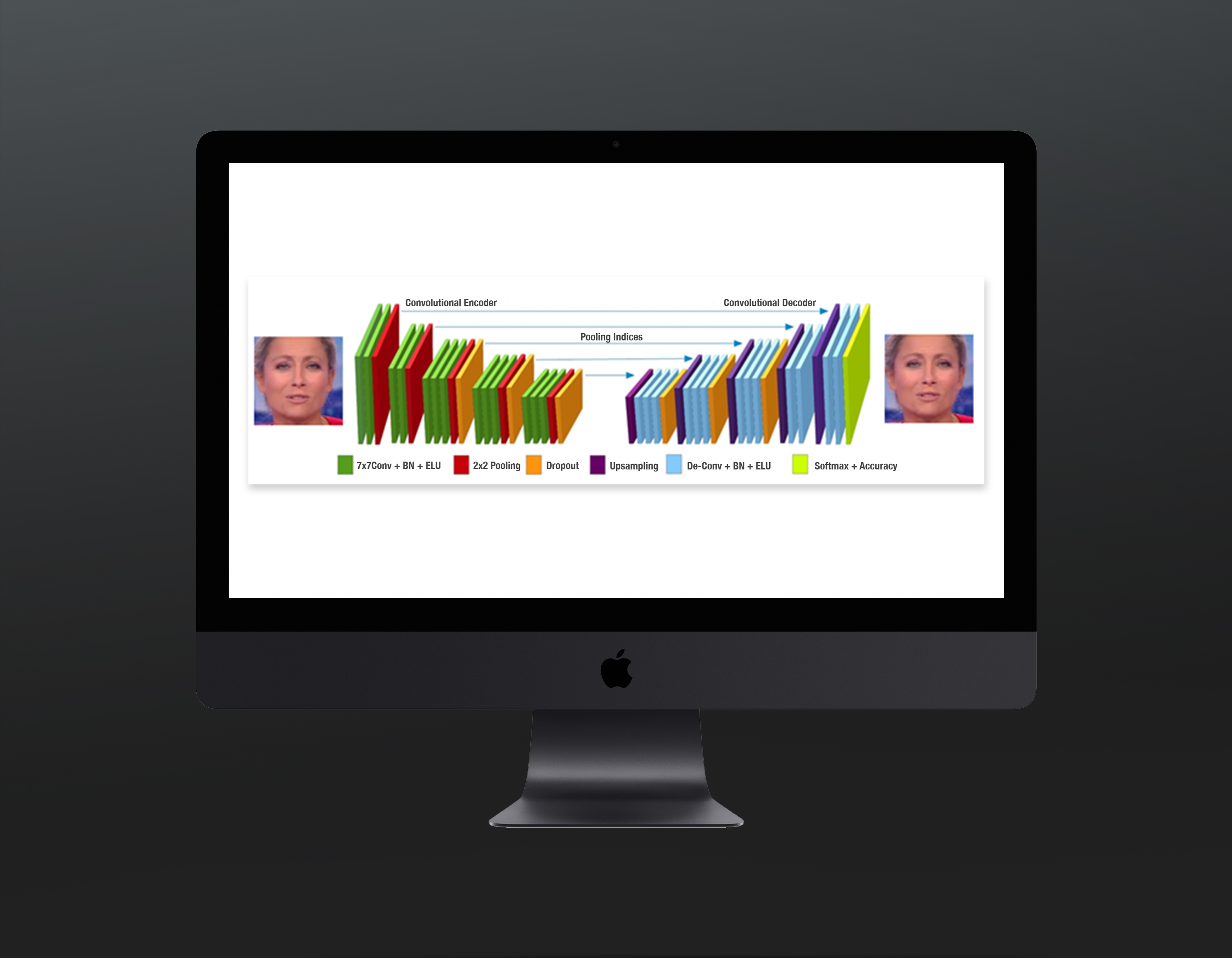
En Deep Learning, c’est pareil, mais au lieu de jouer avec quelques couches et quelques milliers de neurones, nous jouons avec des dizaines de couches et des centaines de milliers de neurones. Dans le contexte très précis du DeepFake, voici à quoi ressemble notre réseau :
Que doit apprendre notre réseau de neurones ?
En entrée, nous lui donnons l’image de la vidéo. Pour être plus précis, nous lui donnons l’image centrée sur le visage.
En sortie, nous lui demandons de retrouver l’image d’entrée. Cela peut paraître paradoxal, mais oui, nous lui demandons « juste » de retrouver l’image d’entrée.
Sur ce schéma, nous pouvons voir deux parties que nous allons maintenant développer.
Décodeur et Encodeur
Notre réseau peut être découpé en 2 parties : l’encodeur et le décodeur.
Le premier module « l’encodeur » a pour rôle de transformer un visage en une représentation « abstraite » du visage. S’il est bien difficile de savoir ce que « capte » réellement un réseau de neurones d’un visage, on peut cependant imaginer qu’il détecte le sourire, la position ouverte ou fermée des yeux, si la personne regarde à gauche ou à droite, etc.
Pour parvenir à cette représentation abstraite, on opère une « réduction » de l’information. Couche après couche, on réduit le nombre de neurones (la forme d’entonnoir du schéma). L’objectif est de forcer le réseau de neurones à « trouver les caractéristiques essentielles » et non pas à réaliser un apprentissage par cœur du visage.
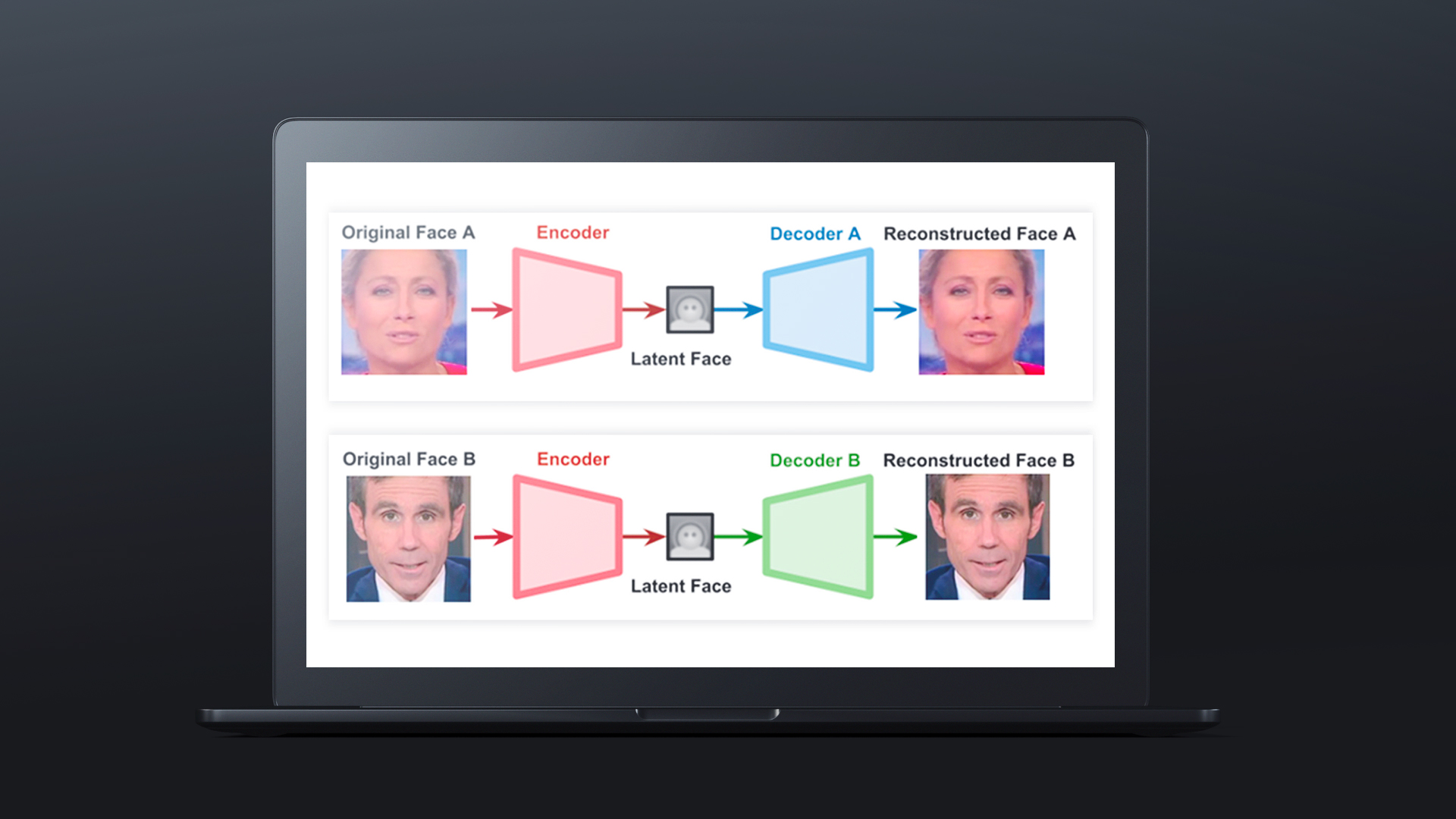
Le deuxième module, le décodeur, a le rôle inverse. D’une représentation abstraite, il doit reconstruire un visage au plus précis, dans les moindres détails, par exemple ici avec Anne-Sophie Lapix.
Une fois l’apprentissage réalisé avec la journaliste, nous faisons la même chose avec David Pujadas. La même chose ? Non, pas tout à fait, le code couleur sur les schémas nous aiguille :
- On réutilise l’encodeur d’Anne-Sophie (A) pour David (B) (encodeur rouge).
- On utilise un nouveau décodeur (vert) pour David.
En effet, sur l’encodeur, le but est de construire une représentation abstraite.
Finalement, quel que soit le visage en entrée, le réseau doit apprendre ce qu’est une bouche ouverte, un sourire, etc. Si on ne fournit qu’un seul visage, le risque est qu’il apprenne les caractéristiques d’un seul visage. C’est donc pour cela que, non seulement nous utilisons le même module pour les 2 visages, mais surtout, nous pouvons le réutiliser dans la réalisation d’autres vidéos fakes.
À l’inverse, pour les décodeurs A et B, nous souhaitons construire un visage très détaillé à partir d’un visage abstrait. Le deuxième module est donc spécifique à chaque visage.
Si nous plaçons Anne-Sophie Lapix en entrée du réseau, l’encodeur « universel » la transforme en visage abstrait. Il ne reste plus qu’à utiliser le décodeur B de David Pujadas et la magie opère.
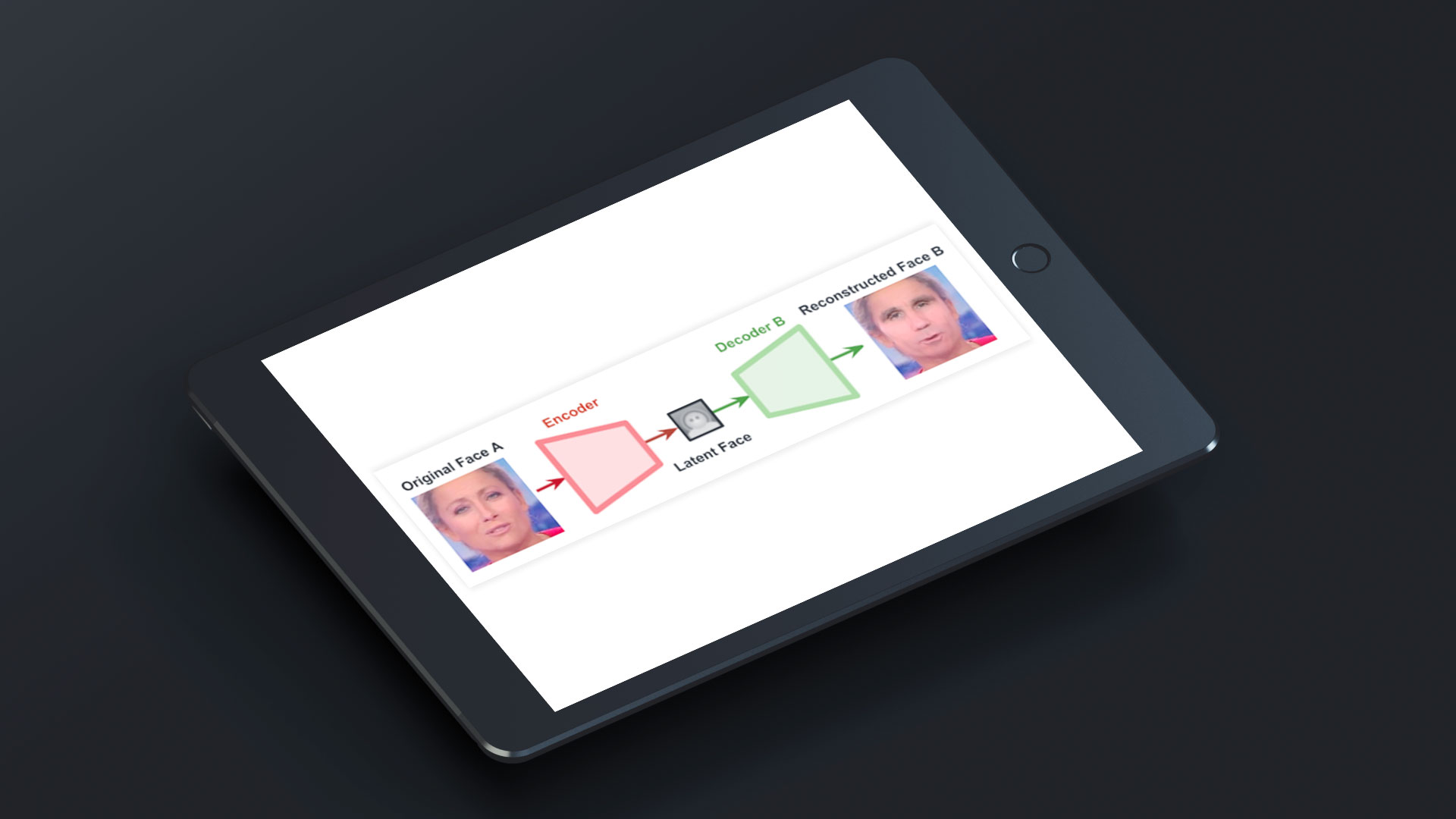
L’avantage ici est que le visage en sortie n’a jamais été rencontré lors de la phase d’apprentissage. Nous obtenons donc un visage entièrement reconstruit comprenant les mimiques de la journaliste française et les trait de son homologue masculin.
Vous allez nous dire : « Dans votre image de sortie, on retrouve le fond de l’image d’entrée alors que le décodeur de David a appris un fond brun et un costume bleu marine… »
Effectivement, nous avons opéré une petite transformation intermédiaire, purement technique.
Sans difficulté, nous apposons un masque sur l’image d’entrée et de sortie. Ensuite nous effectuons un copier-coller du pourtour de l’image d’entrée sur l’image de sortie. Nous appliquons un algorithme de lissage sur les bords ainsi qu’un filtre de couleur afin que le visage de David Pujadas ait la même teinte que le visage d’Anne-Sophie Lapix.
Arrivé à ce stade de l’article, vous connaissez la face cachée du DeepFake. Poursuivons avec la mise en pratique.
Comment faisons-nous ?
Dans cette partie, nous allons vous décrire les étapes de réalisation.
Nous sommes des ingénieurs et allons donc suivre une démarche « Data Science » pour construire notre vidéo. Elle se découpe en 3 phases :
- L’acquisition et la préparation des données
- La phase d’apprentissage
- La mise en œuvre
Phase 1/3 : L’acquisition & la préparation des données
En « science des données », l’acquisition est une partie importante du projet. Ici, la récupération des vidéos ne semble pas la tâche la plus complexe, et pourtant. La qualité de la vidéo est un point extrêmement important dans la réalisation d’un DeepFake. Très vite, vos rendus peuvent être très peu convaincants si votre sélection de vidéos n’est pas bonne.
Voici quelques conseils pour bien choisir vos vidéos :
- Elles doivent être de bonne qualité : SD ou HD
- Elles ne doivent pas non plus être de « trop bonne » qualité car la puissance de calcul est encore limitée
- Choisissez un personnage face caméra qui ne bouge pas trop. Les choix d’un personnage situé dans l’ombre et en mouvement permanent vous offriront un DeepFake de très mauvaise qualité.
- Le visage du personnage choisi doit répondre à une taille minimale : 256 x 256 pixels
Une autre difficulté consiste à trouver des vidéos libres de droit. Il existe des sites pour en trouver mais peu contiennent des contenus comprenant des personnes. L’autre solution est YouTube qui héberge des vidéos dotée de la licence « Creative Commons ».
Tuto YouTube :
Lancer votre recherche. Une fois la recherche effectuée, le bouton « Filtrer » apparaît.
Cliquer dessus puis sur l’option « Creative Commons ». Le tour est joué, récupérez vos 2 vidéos et continuons ensemble.
Le schéma suivant illustre parfaitement la préparation des données :

La première étape consiste à découper votre vidéo en images. Une vidéo étant une succession d’images, il vous suffit de vous doter d’un logiciel de montage.
La seconde est relativement simple également puisqu’elle consiste à enlever les images qui ne nous intéressent pas. Par exemple, nous trions les différents plans proposés et conservons les plus propices à notre DeepFake.
La troisième est un peu plus complexe. Elle consiste à extraire, au sein de notre image source, une image centrée sur le visage de la personne.
Généralement, une image de 256 x 256 pixels suffit, cela dépend bien sûr de la qualité de votre vidéo et de la puissance de votre ordinateur lors de l’apprentissage.
Pour l’extraction, pas de panique, déjà entrainés et prêts à l’emploi, les algorithmes d’IA le font très bien.
Quelques surprises peuvent arriver comme la détection de visages inattendus par l’algorithme tels que :
- Le deuxième personnage dans la scène
- L’image du personnage dans un miroir
- Un portrait dans élément du décor
Ces images sont bien sûr à enlever.
Un algorithme d’IA ne sait pas prendre une vidéo en entrée. Le travail préparatoire de transformation et de nettoyage est donc nécessaire.
Le grand public oublie souvent cette première phase des projets en Intelligence Artificielle. Il faut savoir que l’acquisition et la préparation des données représentent en moyenne 80% d’un projet IA, en particulier lorsqu’il y a un étiquetage manuel à réaliser, ce qui n’est pas le cas ici.
Une fois ces étapes réalisées pour nos deux vidéos, nous passons à la seconde phase.

Phase 2/3 : L’apprentissage
Nous entrons enfin au cœur de l’IA. Nous allons effectuer la phase d’apprentissage durant laquelle notre algorithme tournera plusieurs heures. Nous nous contentons ici d’utiliser des algorithmes prêts et déjà paramétrés.
Pour illustrer l’évolution de l’apprentissage (et sa durée), nous vous donnons les résultats intermédiaires sur Brad Pitt. Nous disposions d’environ une centaine d’images. Un cycle consiste donc à présenter toutes les images, une par une, et aléatoirement en entrée. L’algorithme calcule l’image de sortie puis sa rétropropagation, c’est-à-dire son apprentissage. Il passe ensuite à l’image suivante. Une fois les 100 images présentées, le cycle est terminé. Nous répétons ce processus au cycle suivant.
Au bout de 90 cycles, soit une minute, nous pouvons constater que les visages en sortie sont complètement flous. Cependant, nous pouvons déjà deviner qu’il s’agit d’un visage grâce aux traits identifiés : le nez, les yeux, la bouche, etc.
10 minutes plus tard, il n’y a plus de doute, nous avons bien à faire à un visage. Les traits commencent à se dessiner mais il est encore difficile d’identifier la personne.
Après 1h30, soit 3000 cycles plus tard, la magie commence à opérer. Brad Pitt est bel et bien notre personnage mystère.
Cependant, il y a un hic. L’image n’est pas de très bonne qualité.
C’est à ce moment-là que cela se complique. En une heure et trente minutes, nous parvenons à une image « moyenne ». L’obtention d’une image de bonne qualité nécessite encore quelques heures d’apprentissage.
Au bout de 4h l’image s’améliore mais la qualité n’est pas encore suffisante. C’est finalement au bout de 12h, dans notre cas, que nous obtenons une image de bonne qualité. Les traits sont précis, les dents bien distinctes et les yeux perçants.
Notre deuxième grande étape, la phase d’apprentissage, est désormais terminée. Tout est prêt, nous n’avons plus qu’à appliquer.
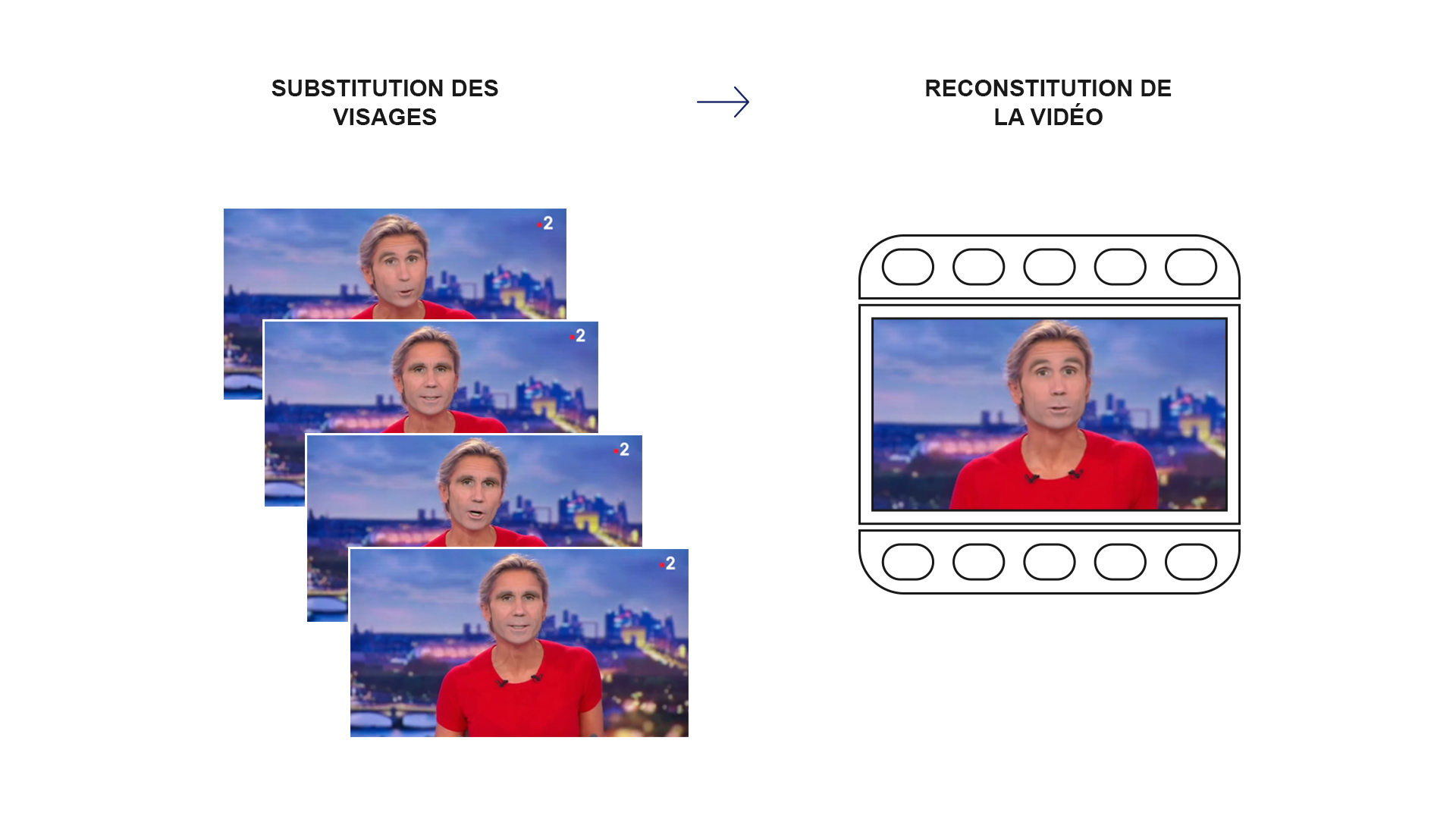
Phase 3/3 : la mise en production
Nous arrivons à la dernière phase de la création de notre DeepFake : l’utilisation de notre algorithme entraîné pour générer la vidéo finale.
Sur chaque visage, nous appliquons notre algorithme. Nous recopions le fond et obtenons ainsi les images finales.
Il n’y a plus qu’à utiliser un logiciel de montage pour transformer les images en vidéo et remettre la bande son d’origine. Le travail est terminé, nous avons notre DeepFake.
Des outils pour les identifier
Nous avons décortiqué ensemble la création de DeepFake. Vous y voyez désormais plus clair dans la construction d’un DeepFake et son fonctionnement. Deux vidéos, un encodeur universel, deux décodeurs et le tour est joué.
Véritable prouesse technologique, ils suscitent beaucoup de débats autour de leur utilisation. Une chose est sûre, les DeepFake font aujourd’hui partie du paysage médiatique. Présents à la télévision, sur les réseaux sociaux et dans les campagnes présidentielles, leur utilisation doit être contrôlée et leur identification améliorée. Afin de les détecter, des outils se développent et auront pour mission de freiner les utilisations malveillantes qui en sont faites.
Ils sont cependant la preuve de la puissance de l’Intelligence Artificielle et ouvrent de nombreuses voies à des univers artistiques tels que le cinéma, la vidéo, l’expérience digitale ou encore l’art moderne.